Like what you see? Subscribe here and get it every week in your inbox!
Issue #219 - May 21, 2023
Here are the top threads of the week, happy reading!
1. Ask HN: Can someone ELI5 transformers and the “Attention is all we need” paper?
Top comment by benjismith
Okay, here's my attempt!
First, we take a sequence of words and represent it as a grid of numbers: each column of the grid is a separate word, and each row of the grid is a measurement of some property of that word. Words with similar meanings are likely to have similar numerical values on a row-by-row basis.
(During the training process, we create a dictionary of all possible words, with a column of numbers for each of those words. More on this later!)
This grid is called the "context". Typical systems will have a context that spans several thousand columns and several thousand rows. Right now, context length (column count) is rapidly expanding (1k to 2k to 8k to 32k to 100k+!!) while the dimensionality of each word in the dictionary (row count) is pretty static at around 4k to 8k...
Anyhow, the Transformer architecture takes that grid and passes it through a multi-layer transformation algorithm. The functionality of each layer is identical: receive the grid of numbers as input, then perform a mathematical transformation on the grid of numbers, and pass it along to the next layer.
Most systems these days have around 64 or 96 layers.
After the grid of numbers has passed through all the layers, we can use it to generate a new column of numbers that predicts the properties of some word that would maximize the coherence of the sequence if we add it to the end of the grid. We take that new column of numbers and comb through our dictionary to find the actual word that most-closely matches the properties we're looking for.
That word is the winner! We add it to the sequence as a new column, remove the first-column, and run the whole process again! That's how we generate long text-completions on word at a time :D
So the interesting bits are located within that stack of layers. This is why it's called "deep learning".
The mathematical transformation in each layer is called "self-attention", and it involves a lot of matrix multiplications and dot-product calculations with a learned set of "Query, Key and Value" matrixes.
It can be hard to understand what these layers are doing linguistically, but we can use image-processing and computer-vision as a good metaphor, since images are also grids of numbers, and we've all seen how photo-filters can transform that entire grid in lots of useful ways...
You can think of each layer in the transformer as being like a "mask" or "filter" that selects various interesting features from the grid, and then tweaks the image with respect to those masks and filters.
In image processing, you might apply a color-channel mask (chroma key) to select all the green pixels in the background, so that you can erase the background and replace it with other footage. Or you might apply a "gaussian blur" that mixes each pixel with its nearest neighbors, to create a blurring effect. Or you might do the inverse of a gaussian blur, to create a "sharpening" operation that helps you find edges...
But the basic idea is that you have a library of operations that you can apply to a grid of pixels, in order to transform the image (or part of the image) for a desired effect. And you can stack these transforms to create arbitrarily-complex effects.
The same thing is true in a linguistic transformer, where a text sequence is modeled as a matrix.
The language-model has a library of "Query, Key and Value" matrixes (which were learned during training) that are roughly analogous to the "Masks and Filters" we use on images.
Each layer in the Transformer architecture attempts to identify some features of the incoming linguistic data, an then having identified those features, it can subtract those features from the matrix, so that the next layer sees only the transformation, rather than the original.
We don't know exactly what each of these layers is doing in a linguistic model, but we can imagine it's probably doing things like: performing part-of-speech identification (in this context, is the word "ring" a noun or a verb?), reference resolution (who does the word "he" refer to in this sentence?), etc, etc.
And the "dot-product" calculations in each attention layer are there to make each word "entangled" with its neighbors, so that we can discover all the ways that each word is connected to all the other words in its context.
So... that's how we generate word-predictions (aka "inference") at runtime!
By why does it work?
To understand why it's so effective, you have to understand a bit about the training process.
The flow of data during inference always flows in the same direction. It's called a "feed-forward" network.
But during training, there's another step called "back-propagation".
For each document in our training corpus, we go through all the steps I described above, passing each word into our feed-forward neural network and making word-predictions. We start out with a completely randomized set of QKV matrixes, so the results are often really bad!
During training, when we make a prediction, we KNOW what word is supposed to come next. And we have a numerical representation of each word (4096 numbers in a column!) so we can measure the error between our predictions and the actual next word. Those "error" measurements are also represented as columns of 4096 numbers (because we measure the error in every dimension).
So we take that error vector and pass it backward through the whole system! Each layer needs to take the back-propagated error matrix and perform tiny adjustments to its Query, Key, and Value matrixes. Having compensated for those errors, it reverses its calculations based on the new QKV, and passes the resultant matrix backward to the previous layer. So we make tiny corrections on all 96 layers, and eventually to the word-vectors in the dictionary itself!
Like I said earlier, we don't know exactly what those layers are doing. But we know that they're performing a hierarchical decomposition of concepts.
Hope that helps!
2. Ask HN: What's your favorite GPT powered tool?
Top comment by sgt
Am I the only one who isn't using ChatGPT on a regular basis?
Though I've made a few attempts to use it, generally I already know the answers to most trivial questions. And by going into more complex questions and scenarios, it becomes apparent that ChatGPT lacks a deep understanding of the suggestions it provides. It turns out to be a pretty frustrating experience.
Also I've noticed that by the time I've crafted intricate prompts, I could have easily skimmed through a few pages of official docs and found a solution.
That said, considering the widespread buzz surrounding ChatGPT, it's entirely possible that I may simply be using it incorrectly.
3. Ask HN: I am overflowing with ideas but never finish anything
Top comment by Ballas
That is a trait of ADHD. Hyperfocus until you find the next thing to hyperfocus on and then completely forget about the previous one.
The best way to deal with it* IMHO is to have a long term goal - and a reason why you want to achieve it. The reason should be chosen so that it motivates you to continue with the project. If you cannot think of a good one that will meet that requirement, then consider switching to a project that you can think of a good reason to keep you motivated. Set targets and then break it down into small tasks that are easy to track and achieve (the same as you probably do professionally). Ideally this task list should be somewhere visible, to remind you of it - along with your long term goal/reason.
edit:
*it referring to the original complaint. I'm not a Psychiatrist.
4. Ask HN: What 60 folks can give career and general life advice for 40 folks
Top comment by PreInternet01
Not quite in my 60s just yet, but close. Anyway:
Work: find your niche. Accept that you're not going to be a hotshot coder/consultant/whatever forever. However, outside of 'fashionable tech' there is an entire world where you can make a comfortable living and nobody cares about your age. That doesn't mean you can stop learning: remaining up-to-date on relevant skills is important, but 'relevant' does a lot of heavy lifting there. Be knowledgeable/reliable instead of trendy.
Leisure: don't put off things you truly want to do until some unspecified later date. You might not make it (see 'health' below). Find at least one activity to enjoy on at least a weekly basis, travel (even if it's close to home), go for walks, spend time with your loved ones.
Health: everything truly and rapidly gets worse once you're 50. Stop smoking now, stop drinking now (or at least moderate a lot), talk to a doctor on a regular basis, take care of your teeth (really).
(That last paragraph is awfully generic, but until such time that we invent time machines, a very important one...)
5. Ask HN: Is YC becoming less of a home for hackers and more for MBA-types?
Top comment by poomer
It does feel like there are more and more startups every YC batch that are just cynical cash grabs. For example, all the recent LLM-related startups that are just UI wrappers around APIs - its hard to imagine that the founders built them for any reason other than to make money, or solely for the reason of wanting to be in YC.
Unfortunately, this is a tech industry problem, not just a YC problem. Tech skills and tech jobs are now seen as a status symbol, and increasingly new entrants in the field are the types of folks who would've gone into law or finance in the past.
6. Ask HN: Has journaling improved your life?
Top comment by jrib
A few years ago I realized my days all kind of blurred together.
So I started journaling. I eventually built a good habit of doing it once a week. Every week, I read the previous entry and then write a new entry. Around the end of the year, I go back and read the whole year.
I prefer to use a physical journal with nice paper and a decent pen.
It has been very transformative for me. I write about my experiences and I write about what I read. I also write about what changes I want to make, and reflect on how changes I wanted to make are going.
Reviewing my thoughts in this way has led me 1) to be more forgiving of myself, focusing more on growth instead of failure and 2) to make incremental progress on objectives I have.
7. Ask HN: How do I make a website in 2023?
Top comment by mchaver
Depends what you are actually trying to build. If it is not too complex you can get pretty far with just HTML, JS/jQuery and CSS.
If your goal is to build a complex single page app then you will do fine with React, Angular or Vue. All of these have a learning curve made more complex by the compilation stages required to get it to the browser, but the documentation made by the developers should be enough to get started.
If you want to become competent without having to waste time tracking down blog posts or Stack Overflow answers for specific questions, go and buy a Udemy course for the particular library you want to use. All of the big ones have good courses that will take you from zero to making your own application. It should give you a strong foundation. The courses are inexpensive if you wait for a sale day. There are often a couple every month.
Finally, I think this is where ChatGPT really shines. It is a great tool for exploring new libraries and solving all the small problems you run into along the way. Imagine all the questions you would want to ask on Stack Overflow but they would get downvoted, you can ask those questions to ChatGPT. Stuff like how do I make a checkbox, why does this piece of state not update like I expect it to, how do I display my components in certain routes, show it your webpack file and ask why your application is not starting, etc.
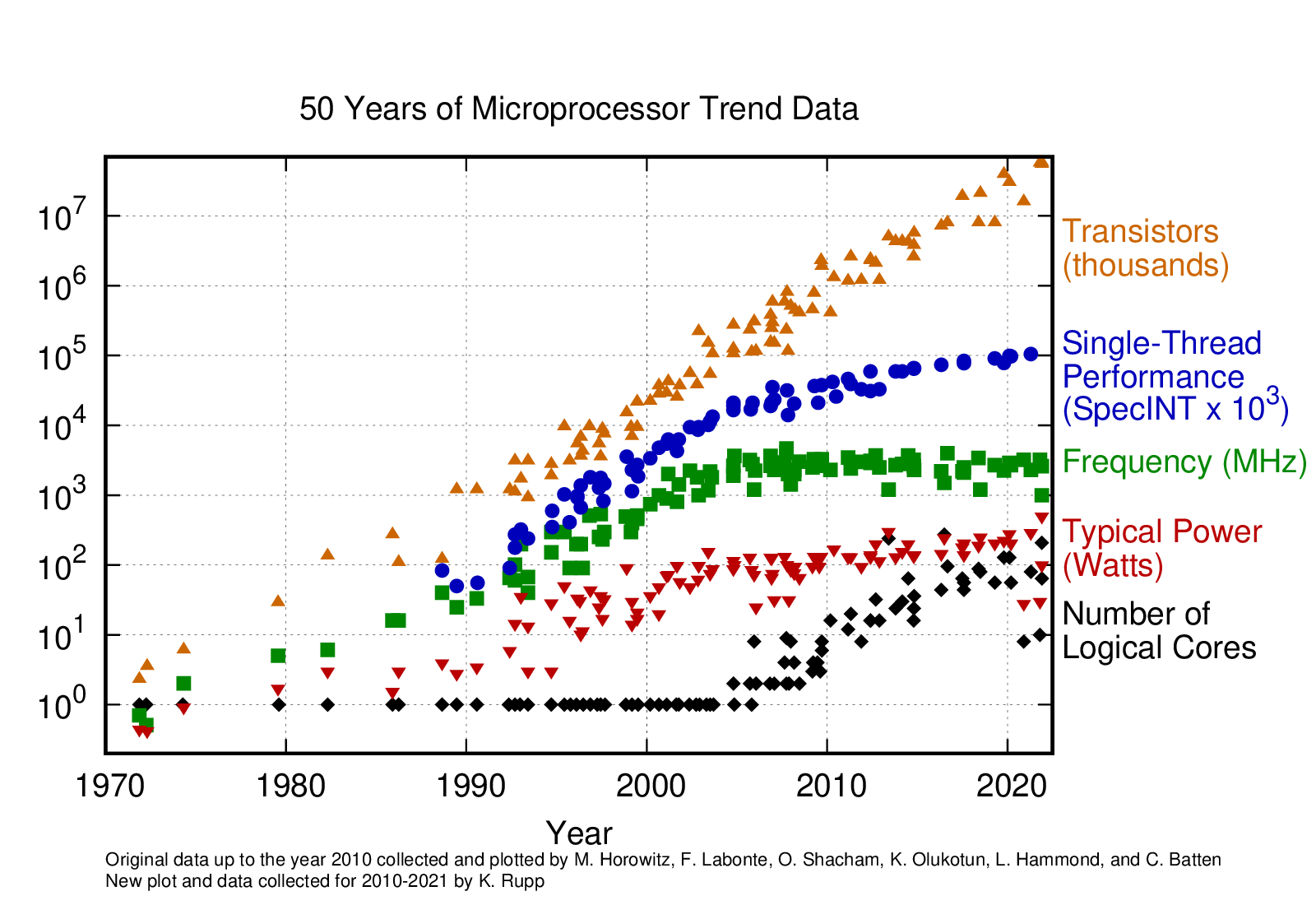
8. Ask HN: Is Moore's Law over, or not?
Top comment by kpw94
Earlier today on HN there was a submission about great CPU stagnation. In the blog post was an interesting link: https://raw.githubusercontent.com/karlrupp/microprocessor-tr...
This graph to me show that while yes technically Moore's law of doubling transistor per "thing Intel or AMD sells you" is still holding, it has ended for single threaded workloads. Moore's law is only holding due to core count increase.
For everyday use of users running multiple simple programs/apps, that's fine. But for truly compute heavy workloads (think a CAD software or any other heavy processing), developers turned to GPUs to get the compute power improvements.
Writing amazing programs taking full advantage of the core count increase is simply impossible (see Amdahl's law). So even if one wanted to rearchitect programs to take full advantage of the overall transistor count from ~2005 to now, they won't be able to.
Compare with pre-2005, where one just had to sit & wait too see their CPU-heavy workloads improve... It's definitely a different era of compute improvements
{kind=link}
9. Ask HN: Where to Feature Startup on Spanish, Portuguese, German, French?
Top comment by polonbike
My readlist in French is https://www.journalduhacker.net/ , as suggested in another comment, and https://linuxfr.org/, covering open source, if it applies to your product. Then Hackernews, but you are already here. Appart from that, it depends on your product. You will need to communicate through the niche channels your SaaS is adressing (aka woodworking channels for a woodworking Saas, etc ...)
10. Ask HN: Will AI result in mass silo-ing of new knowledge?
Top comment by samsquire
As someone who publicly publishes all their ideas everyday in an ideas journal and releases the code of all their side projects on GitHub.
I stand on the shoulders of giants: the people who learned to harvest wheat grain and learnt to mix it with water and heat it into bread.
I don't want to keep my ideas secret if there is a very real chance my ideas can beneficially influence the world, educate or improve people's thinking to make it a superior place.
Like the idea of washing hands to prevent disease or the study of calculus, if someone shares their thoughts, society can get better.
Here's an idea to solve the problem with my attitude - the problem of attribution: "cause coin". What if we could assign numbers or virtually credit causes for our decision making? Wouldn't this provide a paper trail of causality for what happened and why it happened, from people's perspectives at the point of action. Why did you buy this product over this product? (Edit: There's a usecase for blockchain.)
Who needs to do data science with theories when you have direct self reported causality information. Isn't that pseudohonest causality information more useful than unfalsifiable theoretical theories about data?
In the academic realm, we care a lot about attribution but large language models obfuscate causality and attribution.
If someone took my code or idea and built a billion dollar company over it and I didn't receive anything, except for the knowledge that I caused that to happen. Some people would hate that scenario.
Here's another idea: lifestyle subscriptions, you pay your entire salary for a packaged life that includes credits to restaurants, groceries, job, career, transport, products, subscriptions, holidays, savings, investments, hobbies, education. You would need an extremely good planning and lots of business relationships and automation but you could make life really easy for people. Subscribe to a coffee everyday.